Capítulo 6 Independencia de variables categóricas
Las tablas de contingencia se utilizan para examinar la relación entre dos variables categóricas, o bien explorar la distribución que posee una variable categórica entre diferentes muestras.
Hay diferentes cuestiones que surgen al examinar una tabla de contingencia, y en este tema vamos a tratar la cuestión de la independencia.
La independencia de dos variables consiste en que la distribución de una de las variables es similar sea cual sea el nivel que examinemos de la otra. Esto se traduce en una tabla de contingencia en que las frecuencias de las filas (y las columnas) son aproximadamente proporcionales. Esto es equivalente a observar que los porcentajes por columnas(o filas) son similares.
La prueba de independencia \(\chi^2\) (chi-cuadrado) contrasta la hipótesis de que las variables son independientes, frente a la hipótesis alternativa de que una variable se distribuye de modo diferente para diversos niveles de la otra.
Ejemplo:Prioridades en niños y sexo
Vamos a usar la base de datos coolKids.sav donde se recogen las respuestas de unos escolares de 10 a 12 años a los que se les preguntó, entre otras cosas, a qué daban más prioridad de entre tres posibilidades: Tener buenas notas, destacar en los deportes o ser popular entre los compañeros. Examinemos las primeras líneas de la base de datos:
df=read_sav("datos/coolKids.sav", user_na=FALSE) %>% haven::as_factor() | Sexo | Curso | Edad | Raza | Entorno | Escuela | Metas | Notas | Deportes | Apariencia | Dinero |
|---|---|---|---|---|---|---|---|---|---|---|
| Varón | 5 | 11 | Blanco | Rural | Elm | Deportes | 1 | 2 | 4 | 3 |
| Varón | 5 | 10 | Blanco | Rural | Elm | Popular | 2 | 1 | 4 | 3 |
| Mujer | 5 | 11 | Blanco | Rural | Elm | Popular | 4 | 3 | 1 | 2 |
| Mujer | 5 | 11 | Blanco | Rural | Elm | Popular | 2 | 3 | 4 | 1 |
| Mujer | 5 | 10 | Blanco | Rural | Elm | Popular | 4 | 2 | 1 | 3 |
| Mujer | 5 | 11 | Blanco | Rural | Elm | Popular | 4 | 2 | 1 | 3 |
Vamos a estudiar por sexos si por sexo hay diferencias en la distribución de las metas:
df %>% generaTablaChi2PorGrupo(vGrupo = "Sexo",vCuali = "Metas") %>%
select(1:5) %>%
knitr::kable(booktabs=T) %>%collapse_rows(1:5,valign = "top")| Variable | Valores | Varón | Mujer | p |
|---|---|---|---|---|
| Metas | Notas | 51.5(117) | 51.8(130) | <0.001* |
| Metas | Popular | 22.0(50) | 36.3(91) | <0.001* |
| Metas | Deportes | 26.4(60) | 12.0(30) | <0.001* |
La significación que se observa en la tabla (p), es la de la prueba Chi-cuadrado. Nos indica que las diferencias en porcentajes que se aprecian en las columnas de niños y niñas van más allá de lo que se esperaría que ocurriese por puro azar.
Con un poco de atención se observa porcentajes similares de niños y niñas en cuanto a la importancia que tienen para ellos las notas. Donde más diferencia se observa entre los sexos es en la preferencia que muestran muchos chicos por los deportes y muchas chicas por la popularidad.
Gráficamente podríamos mostrarlo con diagramas de barras apiladas:
dftmp=df %>% select(Sexo,Metas) %>% mutate(cuenta=1) %>% group_by(Sexo,Metas) %>% tally() %>% mutate(fraccion=n/sum(n))
ggplot(dftmp, aes(fill=Metas, y=fraccion, x=Sexo)) +
geom_bar( stat="identity", position="fill")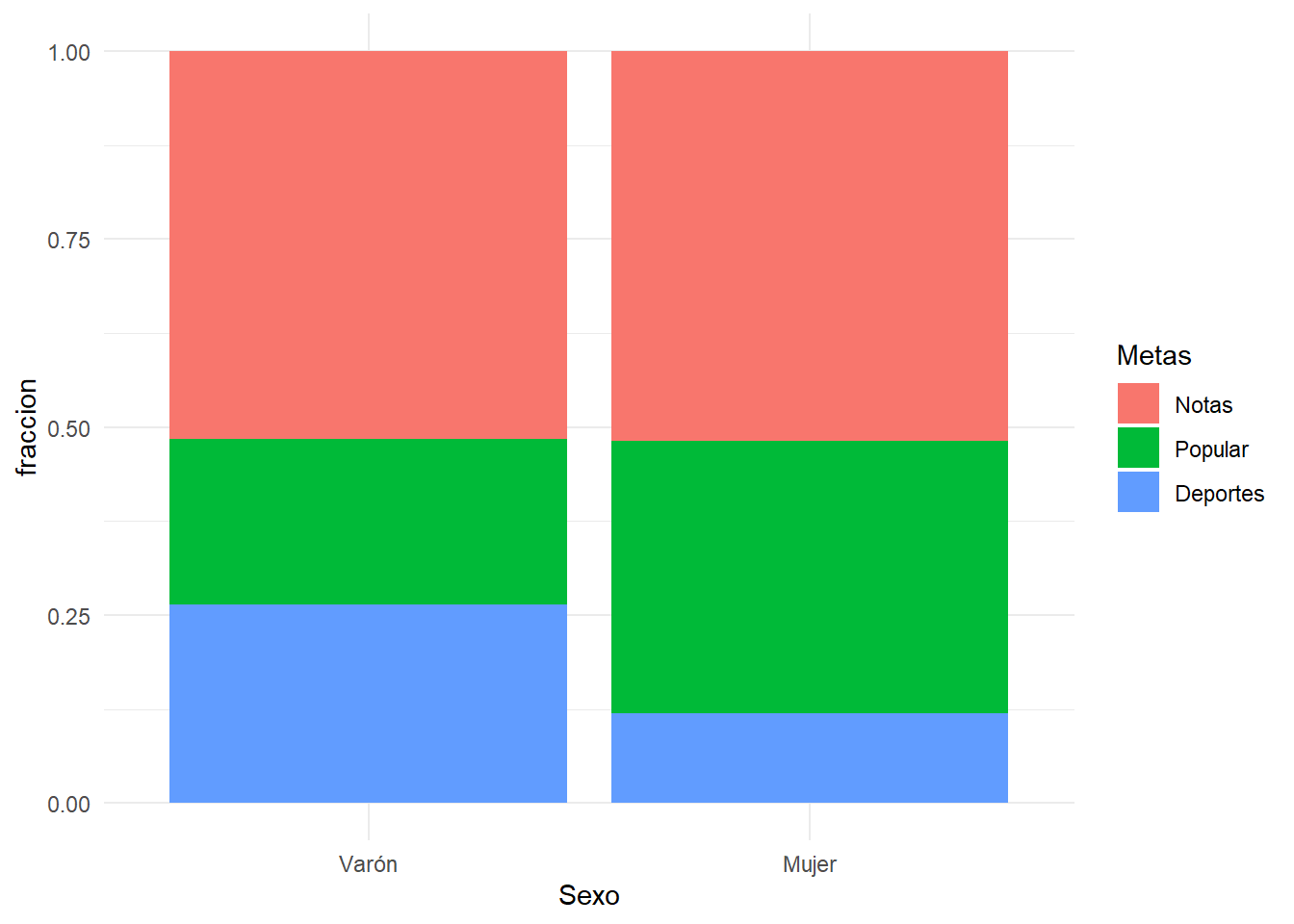
Otra forma interesante de mostrarlo consiste en utilizar gráficos de mosaicos, donde se utiliza un área para cada combinación de las dos variables, proporcional a las frecuencias observadas. Observe que son ligeramente más anchos los mosaicos de las mujeres que los de los varones. Esto refleja que en el estudio participa una cantida liéramente mayor de hombres que de mujeres.
ggplot(data = df) +
geom_mosaic(aes(x = product(Metas,Sexo), fill=Metas), na.rm=TRUE) +
labs(x="Sexo", y="Metas",title='Metas por Sexo')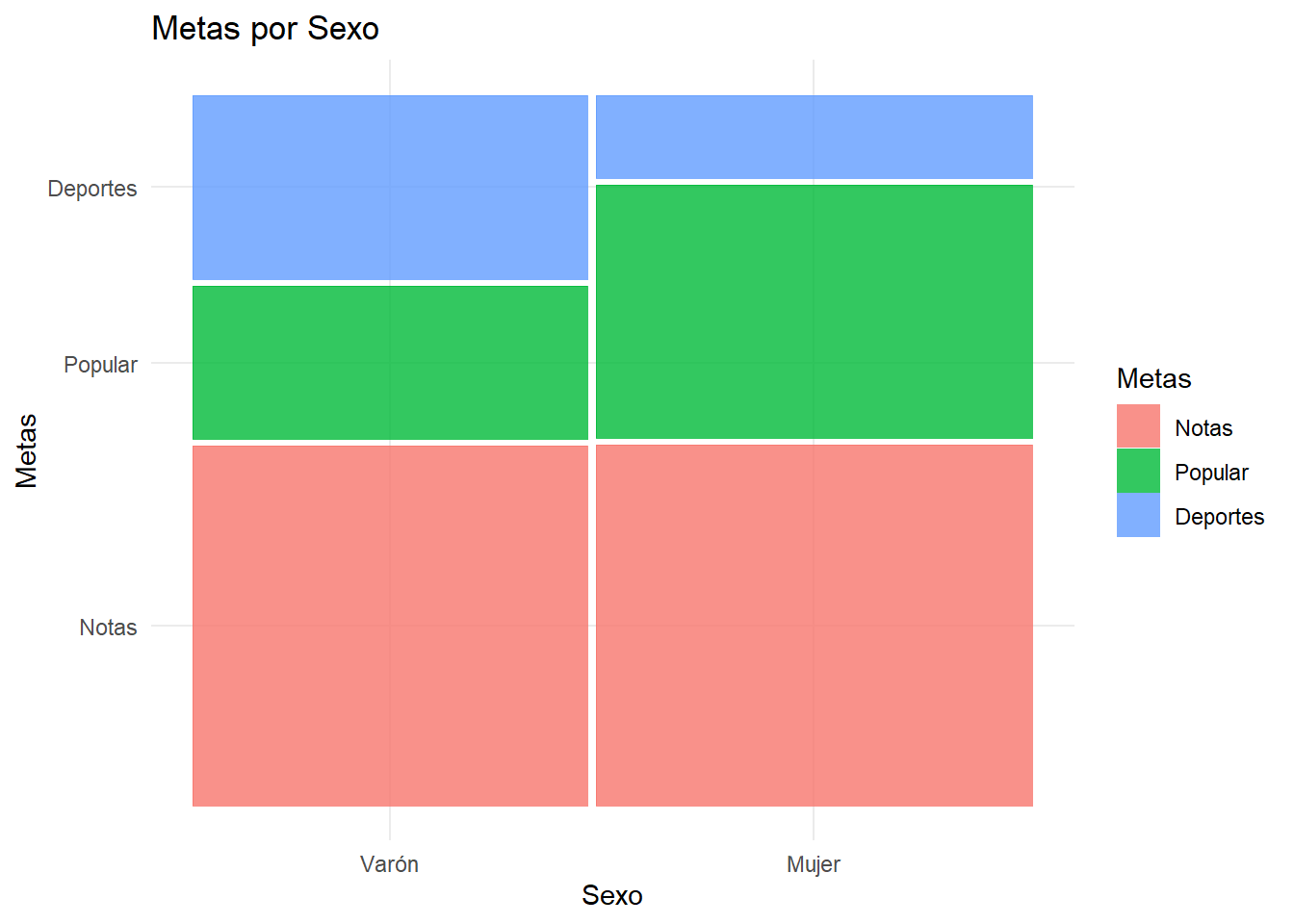
Usando SPSS podemos conseguir tanto las frecuencias como los porcentajes y resultado de la prueba chi-cuadrado en el menú: “Analizar - Estadísticos descriptivos - Tablas de contingencia…”. Allí situamos en columnas la variable Sexo, y en filas ponemos Metas. En el botón Casillas marcamos los porcentajes por columnas. En el botón “Estadísticos…” para marcar seleccionamos la prueba chi-cuadrado de Pearson.
Podríamos afinar más nuestro estudio y ver si estas diferencias entre niños y niñas se presentan también según el Entorno (urbano, suburbano o rural) de los niños. Para ello podríamos realizar una prueba chi-cuadrado en cada entorno:
df %>% generaTablaChi2PorGrupo_Tiempo(vGrupo = "Sexo", vCuali = "Metas", vTiempo = "Entorno") %>%
select(2,3,4,5,6) %>%
knitr::kable(booktabs=T) %>%collapse_rows(1:5,valign = "top")| Tiempo | Valores | Varón | Mujer | p |
|---|---|---|---|---|
| Rural | Notas | 31.8(21) | 43.4(36) | 0.025* |
| Rural | Popular | 28.8(19) | 37.3(31) | 0.025* |
| Rural | Deportes | 39.4(26) | 19.3(16) | 0.025* |
| Suburbano | Notas | 57.3(51) | 58.1(36) | 0.030* |
| Suburbano | Popular | 22.5(20) | 35.5(22) | 0.030* |
| Suburbano | Deportes | 20.2(18) | 6.5(4) | 0.030* |
| Urbano | Notas | 62.5(45) | 54.7(58) | 0.003* |
| Urbano | Popular | 15.3(11) | 35.8(38) | 0.003* |
| Urbano | Deportes | 22.2(16) | 9.4(10) | 0.003* |
ggplot(data = df) +
geom_mosaic(aes(x = product(Metas,Sexo), fill=Metas), na.rm=TRUE) +
labs(x="Sexo", y="Metas",title='Metas por Sexo') + facet_grid(Entorno~.)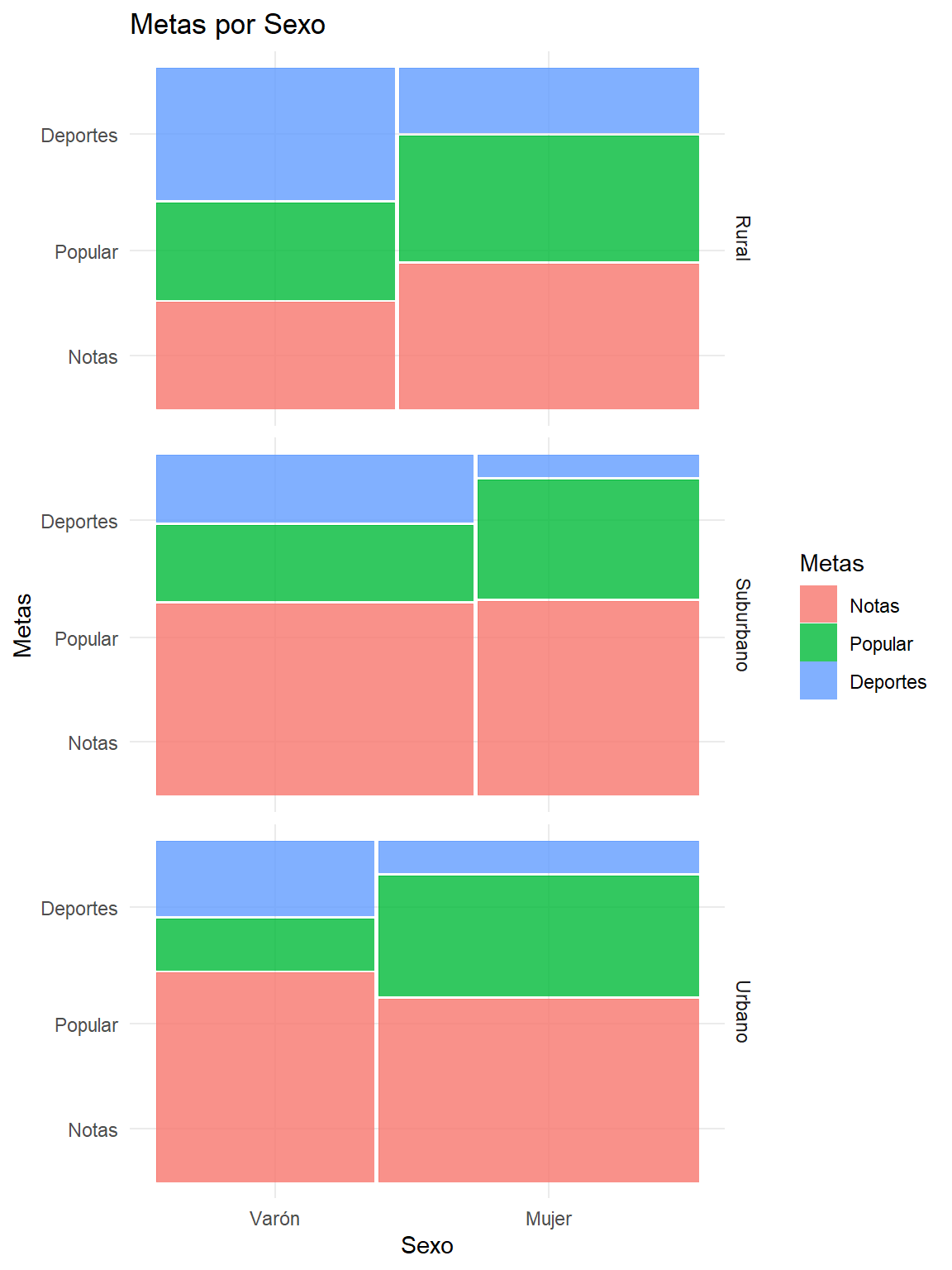
Para hacer lo mismo con SPSS, en el mismo diálogo donde hacíamos tablas cruzadas, pasamos la variable Entornos al campos Capas.
6.1 Limitaciones de la prueba de independencia
El contraste de independencia tiene muy pocas limitaciones, aunque es conveniente hacer algunas observaciones:
Para contrastar la independencia se suele usar el estadístico chi-cuadrado de Pearson. Su cálculo se basa en calcular la diferencia entre las observaciones observadas para cada par de modalidades de las variables (casillas), y las que serían de esperar en caso de que se satisficiese la condición de independencia. Para que se pueda considerar correcta la significación calculada por el estadístico chi-cuadrado de Pearson, se debe cumplir que las frecuencias esperadas no sean muy pequeñas (inferiores a 5) más que en unas pocas casillas. Si es en muchas las casillas donde esto ocurre (más del 20% por ejemplo) se debe usar una prueba que no incluya aproximaciones, como la prueba exacta de Fisher. Esta la ofrece cualquier programa como opción cuando se hace este tipo de contrastes.
Si las muestras son muy grandes, la prueba de independencia dará resultados significativos incluso donde, posiblemente, consideremos que las diferencias no sean en realidad clínicamente interesantes. Es conveniente una inspección visual para confirmar si las diferencias observadas por filas (o columnas, como prefiramos), nos parecen de interés.
Si las variables poseen muchos niveles posiblemente la prueba no resulte de mucho interés, ya que es lógico esperar que se encuentren diferencias. Eso ocurre si por ejemplo una de las variables es numérica y no hemos agrupado los posibles valores en una cantidad adecuada de intervalos.
Si una de las variables es numérica u ordinal, posiblemente queramos hacer algo más que contrastar la simple independencia. Después de todo, esto no es tan informativo como saber que en cierto grupo los valores son significativamente mayores que en otro. Lo aconsejable es usar pruebas de tipo t-student, anova o contrastes no paramétricos comos los que se tratan en otros temas.
El contraste de chi-cuadrado sirve para contrastar la independencia. No hay que considerarla como una medida de la asociación entre variables. Si buscamos estudiar la asociación de variables tenemos otros métodos a nuestra disposición como regresión logística que trataremos más adelante.