df=read_sav("datos/lectura-anova.sav", user_na=FALSE) %>% haven::as_factor() 4 Diferencias que presenta una variable numérica entre dos grupos
En este capítulo veremos procedimientos para contrastar si las diferencias numéricas obtenidas al comparar dos tratamientos (o dos poblaciones) son lo suficientemente grandes como para que su única causa sea atribuible al azar.
Este tipo de pruebas se suelen usar cuando se elige una muestra de individuos que han seguido cierto tratamiento (por ejemplo, un placebo), y otra muestra que ha recibido otro tratamiento (por ejemplo, un fármaco de pruebas).
Dependiendo de cómo se construyan ambas muestras, clasificamos el experimento en dos clases:
Muestras apareadas: Cuando en realidad no hay dos grupos de pacientes, si no que solo hay un grupo de ellos, pero de cada individuo se tienen dos medidas. Esto puede ser debido por ejemplo a que se ha medido cada uno en dos oacasiones (antes y después de un tratamiento) o se ha medido al pacientes con dos aparatos que deberían haber dado un resultado similar.
Muestras independientes: Este es el caso más común, en el que realmente si hay dos grupos diferentes de individuos, cada uno con una medición numérica. Se supone que los individuos de un grupo de tratamiento han sido extraídos independientemente de los del otro.
4.1 Muestras apareadas o relacionadas
Aparecen por ejemplo en los estudios de pacientes “antes y después”, es decir, cuando en un una base de datos de de pacientes tenemos dos columnas de datos numéricos, una correspondientes a los valores antes del tratamiento y otra correspondientes al valor después. En este caso también decimos que cada individuo es su propio control.
Hay otros ejemplos de estudios con apareamiento
Se deben realizar de modo apareados los estudios en que al medir una variable sospechamos de más fuentes de variabilidad además del tratamiento. Por ejemplo, si creemos que el sexo de los individuos puede influir notablemente en la variable que medimos y queremos anular el efecto tenemos varias posibilidades:
Hacer un estudio con todos los individuos del mismo sexo en cada muestra, y otro con todos los individuos del otro sexo. A esto se le denomina estratificar por sexos. En este caso lo que tenemos son dos estudios con muestras independientes.
Asociar a cada individuo del primer grupo, un individuo “que se parezca” del segundo. Por ejemplo, si pensamos que conjuntamente el sexo y la edad pueden influir en el resultado, podemos hacer que por cada individuo del primer grupo, se elija un individuo del segundo, del mismo sexo y de edad similar. A pesar de las dificultades que comporta hacer un estudio con esas características, habremos reducido la posibilidad de que las variables sexo y edad hayan influido mucho en las diferencias observadas entre tratamientos.
4.1.1 Hipótesis nula en estudios apareados
En los contrastes con muestras apareadas, la hipótesis nula es que no la distribución de los valores en una y otra medición son similares. Como en todo contraste de hipótesis, se declara que el efecto es estadísticamente significativo si la significación calculada es inferior a cierta cantidad pequeña (5% o 1% típicamente).
Los contrastes se realizan calculando las diferencias existentes entre cada observación de un grupo y la observación asociada en el segundo. Si las mencionadas diferencias tienen una distribución aproximadamente normal o bien la muestra es grande, la prueba que se suele usar es la t-student para muestras apareadas. Esta prueba funciona del siguiente modo. Si se dan las condiciones de validez (las diferencias son normales), las diferencias deberían ser aproximadamente normales de media cero. Si al calcular la media de las diferencias, el valor obtenido en la muestra no es consistente con una posible media de cero, se rechaza la hipótesis nula. Es decir, si la diferencia entre lo observado y la hipótesis nula no es atribuible al puro azar, aceptamos que hay diferencias entre los grupos.
Una prueba menos exigente es el contraste no paramétrico de Wilcoxon. Este último considera las diferencias entre cada observación y su control. Si la hipótesis nula fuese cierta, las diferencias negativas serían similares en cantidad y tamaño a las diferencias positivas. La prueba de Wilcoxon examina la discrepancia existente entre los resultados observados y la predicción de la hipótesis nula.
Ejemplo
Se estudia si mejoran unos niños su velocidad de lectura en palabras por minuto. Para ellos se les mide al inicio de un estudio, se les vuelve a medir tras una intervención. Se toma nota de la diferencia entre la velocidad final y la inicial. Puede descargar los datos del experimento en la base de datos lectura-anova.sav. La exploración de los primeros casos, ordenados de menor a mayor diferencia nos ofrece:
df %>% head() %>% knitr::kable(booktabs=T)| Grupo | Antes | Despues | Diferencia | gr1 | gr2 |
|---|---|---|---|---|---|
| Control | 10.0 | 19 | 9.3 | 0 | 0 |
| Control | 7.0 | 20 | 13.0 | 0 | 0 |
| Técnica I | 6.5 | 23 | 16.2 | 1 | 0 |
| Técnica I | 9.5 | 19 | 9.5 | 1 | 0 |
| Control | 7.5 | 16 | 8.5 | 0 | 0 |
| Técnica II | 7.5 | 17 | 9.5 | 0 | 1 |
Ya que los datos están ordenados de forma que los peores resultados se muestran primero, y estos han experimentado mejoría, parece que evidentemente vamos a encontrar gran diferencia en contra de la hipótesis nula. Veamos qué distribución presentan las diferencias:
ggplot(df, aes(x=Diferencia))+geom_histogram(fill="lightblue")+ geom_rug(sides = "b", aes(y = 0), position = "jitter", colour = "blue")+coord_cartesian(xlim=c(0,20))+geom_vline(xintercept = 0,lty=2,col="red")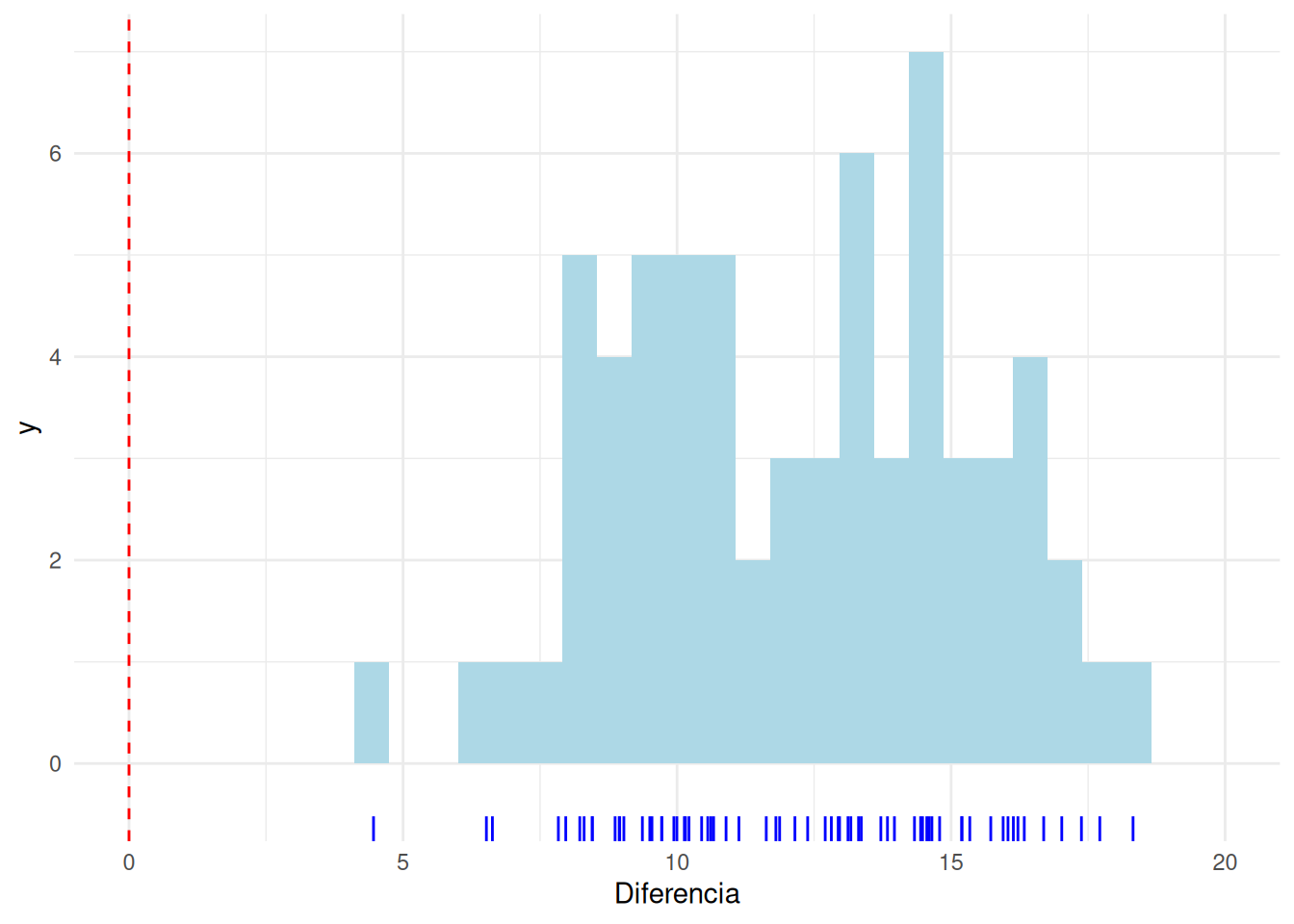
Se ve que todos los individuos han mejorado. la evidencia contra la hipótesis nula la encontramos en esta tabla
et <- function(x) sd(x) / sqrt(length(x))
ic_inf <- function(x) t.test(x, mu = 0)$conf.int[1]
ic_sup <- function(x) t.test(x, mu = 0)$conf.int[2]
p <- function(x) t.test(x, mu = 0)$p.value
# Tabla
datasummary(
Diferencia ~ N + Mean + et + ic_inf + ic_sup + p, data=df
)| N | Mean | et | ic_inf | ic_sup | p | |
|---|---|---|---|---|---|---|
| Diferencia | 66 | 12.15 | 0.39 | 11.38 | 12.92 | 0.00 |
La diferencia observada en los niños representa una mejoría de más de 12 palabras por minuto. Sea cual sea la mejoría media si se aplicase en toda la población de niños similares a estos, los datos observados están en contra de la hipótesis nula de no mejoría (p<0.001). Tenemos una confianza del 95% de que sea cual sea la mejoría media, el valor real está en algún lugar entre 11 y 13 palabras por minuto (redondeando).
NotaSPSS y Jamovi
En SPSS podemos realizar este calculo seleccionando el menú: “_Analizar - Comparar medias - prueba T para muestras apareadas”. Allí marcamos el par de variables Antes y Después. También podríamos haber elegido el menú”_Analizar - Comparar medias - prueba T para una muestra” y haber trabajado con la variable Dferencia. El resultado es el mismo.
En Jamovi podemos usar el menú “_Análisis - Pruebas t - Prueba t para muestras apareadas”. Allí marcamos el par de variables Antes y Después. También podríamos haber elegido el menú “_Análisis - Pruebas t - Prueba t para una muestra” y haber trabajado con la variable Diferencia.
4.2 Dos Muestras independientes
Sirven para tratar problemas como el de si el nivel de hierro es similar en los individuos que padecen determinada enfermedad frente a los individuos sanos. Para ello podríamos elegir una muestra de individuos enfermos y otra de sanos, y comparar si los valores de una muestra tienen tendencia a ser mayores que los de la otra.
En los contrastes con muestras independientes, la hipótesis nula es que los valores obtenidos en una y otra muestra son similares, frente a la hipótesis alternativa de que son diferentes. El valor obtenido en la significación nos permite decidir si se rechaza o no la hipótesis nula.
Hay varias maneras de realizar este tipo de contrastes:
Prueba t-student para dos medias: Se basa en contrastar si las medias de cada grupo son similares. Este tipo de contrastes es válido cuando se da alguna de las siguientes condiciones:
Las desviaciones típicas/varianzas son similares y las observaciones de cada muestra son normales.
Las desviaciones típicas/varianzas son similares y los tamaños muestrales son grandes.
Hay diferencia notable entre las varianzas de cada grupo, pero los tamaños de cada muestra son similares y además las muestras son grandes o aproximadamente normales.
Pruebas no paramétricas para muestras independientes: No requieren ningún tipo de suposición sobre la distribución de las muestras. Esto permite que se puedan usar con variables discretas u ordinales. Pruebas populares son las de Mann-Whitney, Wilcoxon o la prueba de Kolmogorov-Smirnov de dos muestras.
En el caso de que queramos aplicar la prueba t-student, debemos tener en cuenta que esta se ve muy afectada en caso de que las muestras no estén similarmente dispersas, y es necesario hacer una corrección. Debemos comprobar que no existan observaciones anómalas. Disponemos del contraste de Levene para la igualdad de varianzas. Se suele recomendar al usuario elegir un nivel de significación alto para esta prueba (hasta el 15%).
Ejemplo
Se cree que la ingesta de calcio reduce la presión sanguínea. Para contrastarlo se decidió elegir a 21 individuos de características similares para participar en un estudio. A 10 de ellos elegidos al azar, se les asignó un tratamiento consistente en un suplemento de calcio durante 3 meses y se observó la diferencia producida en la presión arterial (la que había “antes” menos la que había “después”). A los 11 individuos restantes se les suministró un placebo y se midió también la diferencia. Los datos podemos encontrarlos en la base de datos calcio.sav, de la que exploramos las primeras líneas:
df=read_sav("datos/calcio.sav", user_na=FALSE) %>% haven::as_factor()
df %>% head() %>% knitr::kable(booktabs=T)| Grupo | Antes | Despues | Diferencia |
|---|---|---|---|
| Placebo | 110 | 121 | -11 |
| Calcio | 111 | 116 | -5 |
| Placebo | 114 | 119 | -5 |
| Calcio | 110 | 114 | -4 |
| Calcio | 112 | 115 | -3 |
| Placebo | 102 | 105 | -3 |
solo nos interesa la variable Diferencia comprarada entre ambos grupos, pero de todas formas vamos a examinar las mediciones Antes. La razón es que al realizar un experimento, repartimos a los individuos en dos grupos, y estamos muy interesados en que los dos grupos sean muy similares en el punto de partida (medición basal):
grid.arrange(
ggplot(df,aes(x=Grupo,y=Antes))+geom_boxplot(fill="lightblue"),
ggplot(df,aes(x=Grupo,y=Diferencia))+geom_boxplot(fill="lightblue"),
ncol=2)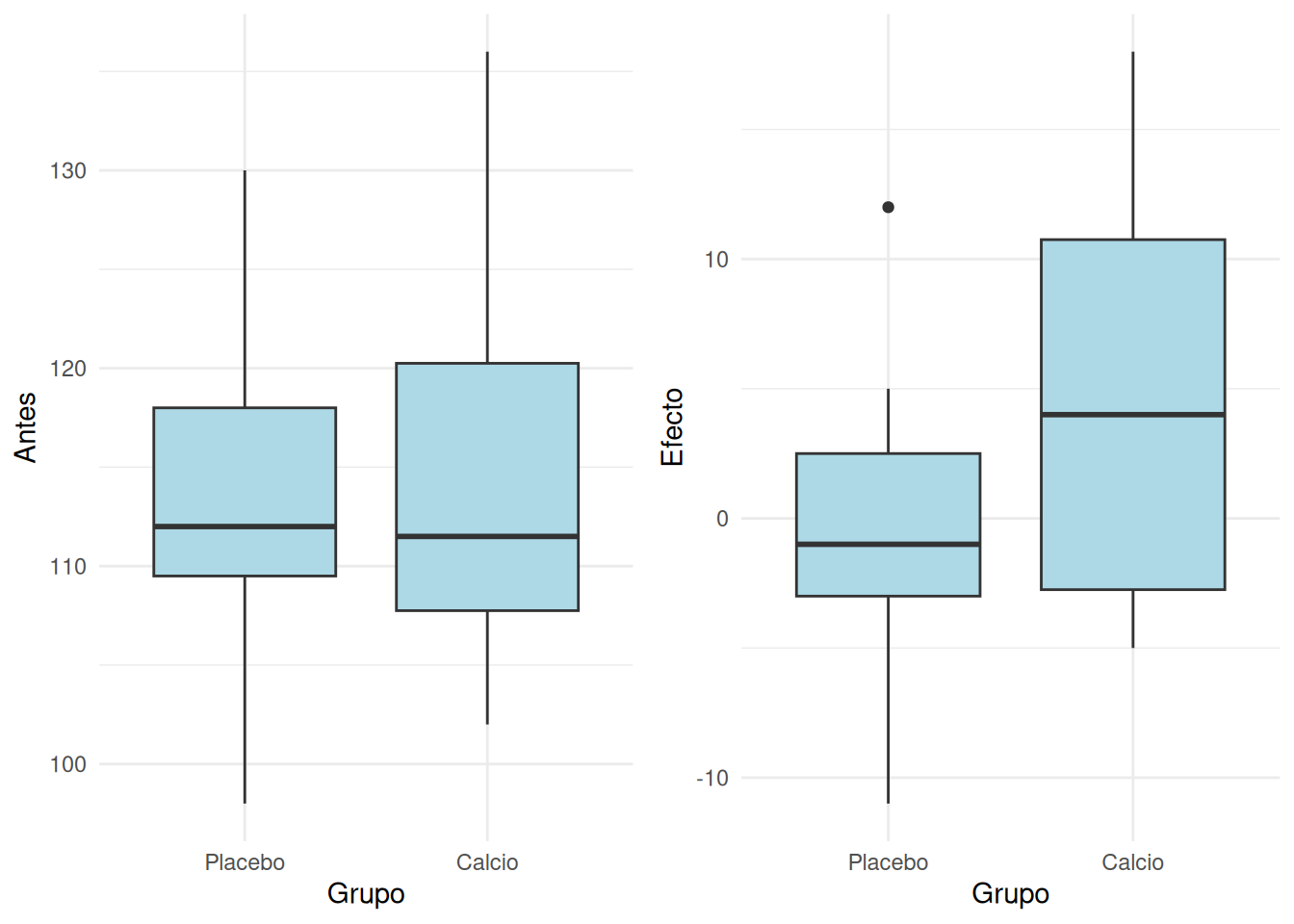
Se aprecia que los dos grupos eran similares al iniciarse el experimento. Sin embargo el grupo de que tomo el Placebo practicamente se quedó igual, y el que tomó Calcio experimentó una mejoría. Nos queda por saber si esta mejoría es explicable por el azar o va más allá (diferencia estadísticamente significativa entre grupos).
vNumericas=c("Antes","Diferencia")
Media <- function(x) mean(x, na.rm = TRUE)
ET <- function(x) sd(x, na.rm = TRUE) / sqrt(sum(!is.na(x)))
Dif <- function(x) {
g <- split(x, df$Grupo)
mean(g[[2]], na.rm = TRUE) - mean(g[[1]], na.rm = TRUE)
}
ET_dif <- function(x) {
t_test <- t.test(x ~ df$Grupo)
return(t_test$stderr) # Extrae el error estándar de la diferencia
}
P <- function(x) {
t_test <- t.test(x ~ df$Grupo)
return(t_test$p.value)
}
form <- as.formula(paste(
paste(vNumericas, collapse = " + "),
"~ Grupo * (Media + ET) + (Dif + ET_dif + P)"
))
datasummary(
formula = form,
data = df,
fmt = 2,
title = "Comparación de Medias: Descriptivos y Contraste t-test"
)| Placebo | Calcio | ||||||
|---|---|---|---|---|---|---|---|
| Media | ET | Media | ET | Dif | ET_dif | P | |
| Antes | 113.27 | 2.72 | 114.90 | 3.43 | 1.63 | 4.38 | 0.71 |
| Efecto | -0.27 | 1.78 | 5.00 | 2.76 | 5.27 | 3.29 | 0.13 |
A la vista de los resultados, entre el grupo Calcio y el Placebo no hay diferencias estadísticamente significativas, no solo al inicio del experimento, si no que el cambio producido en los individuos también es compatible con la hipótesis nula de que obtienen resultados similares. Las significaciones obtenidas se han realizado tanto con la prueba paramétrica de la t-student como con una prueba no paramétrica. Ambas obtienen conclusiones similares.
NotaSPSS y Jamovi
Podemos realizar la prueba paramétrica en SPSS en el menú: “Analizar - Comparar medias -Prueba t para muestras independientes”. En la variable Grupo hemos de indicar que comparamos los grupos 0 (Placebo), con el grupo 1 (Calcio), pues así es como se han codificado numéricamente las variables. El el campo de Variables de prueba situamos las variables Antes y Diferencia. La prueba no paramétrica está en un diálogo análogo que obtenemos en el menú “_Analizar - Pruebas no paramétricas - Cuadros de dialogo antiguos - 2 muestras independientes”
En Jamovi tanto las pruebas paramétricas como la no paramétricas están en el menú “_Análisis - Pruebas t - Prueba t para muestras independientes”, seleccionando checkbox bajo el título “Pruebas”.
Una representación gráfica de los intervalos de confianza muestra que ambos tienen el común el valor cero. Es decir, ninguno de ellos puede decirse que presente una mejoría significativa. ¿Podría interpretarse como que entre ellos no hay diferencia? Esto es algo que no se deduce directamente mirando a los intervalos de confianza, aunque nuestra intuición nos indique que no deben haber mucha diferencia entre ellas.
resumen=df %>% gather(Variable,Valor,-Grupo) %>%
group_by(Grupo,Variable) %>%
summarise(Media=mean(Valor),
n=length(Valor),
IC=sd(Valor)/sqrt(n)*qt(0.975,n-1))
ggplot(resumen %>% filter(Variable=="Diferencia"), aes(x=Grupo,y=Media)) +
geom_errorbar(aes(ymin=Media-IC,ymax=Media+IC),width=0.2, size=1, color="navyblue")+
geom_point( size=4, shape=21, fill="white")+ylab("Diferencia")+
geom_hline(yintercept=0,lty=2,color="red")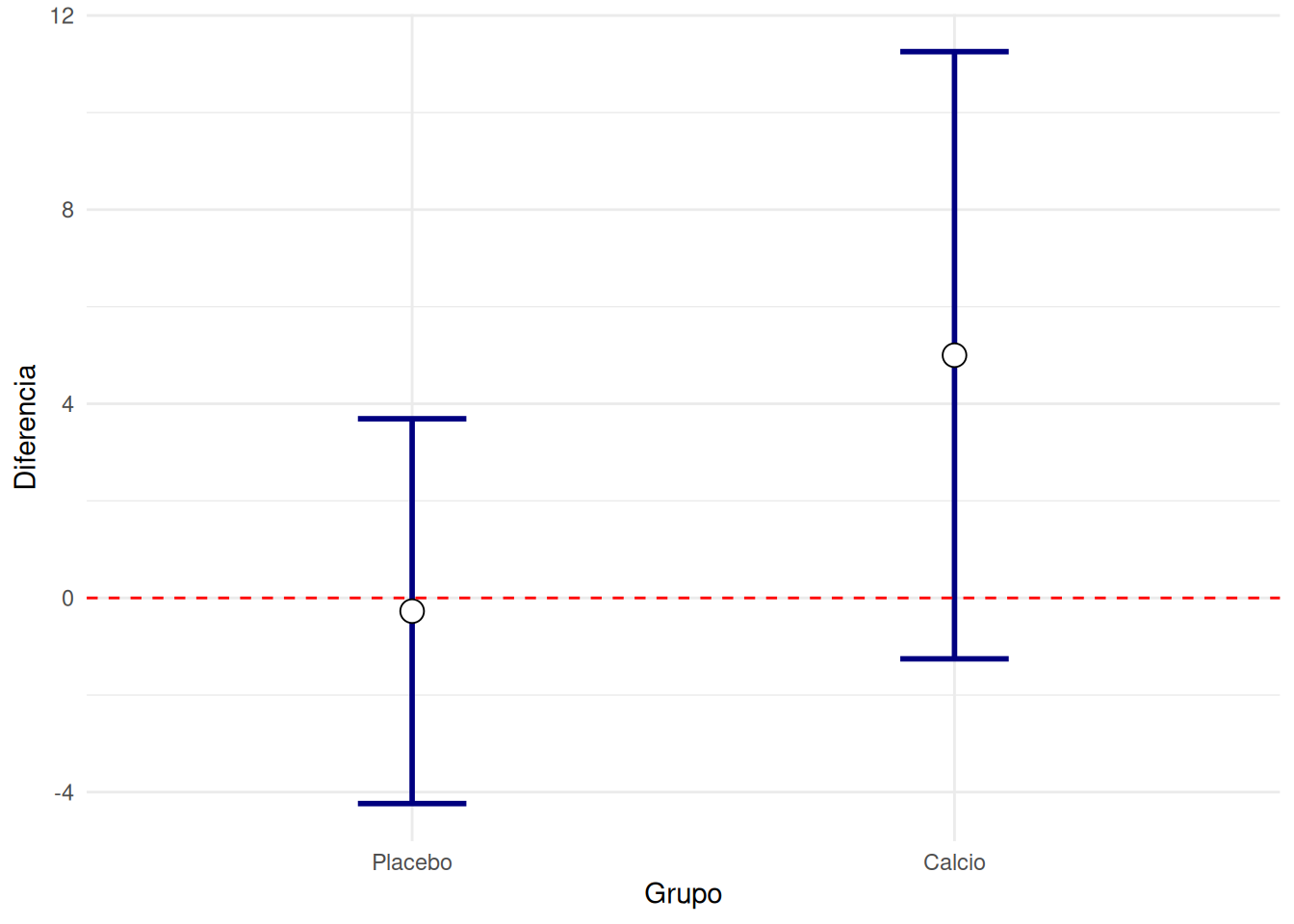
¿Es lo mismo que la diferencia entre dos grupos sea significativa que el que sus respectivos intervalos de confianza para la media no se toquen?
Parecería que es lo mismo, pero no es así. La realidad es que si hay diferencia significativa entre la media de dos grupos, entonces los intervalos de confianza se tocan nada o muy poco. Vamos a ilustrarlo retomando la base de datos 2poblaciones-Mismotrabajo-DiferenteNutricion.sav.
Vamos a usar tanto las pruebas t-student como las no paramétricas para estudiar las diferencias entre los individuos de Málaga y Tanger en todas las variables numéricas.
Normalmente en una publicación científica pondríamos como tabla de resultados algo similar a esto:
vNumericas=names(df) %>% setdiff("Grupo")
elige_test <- function(data, var, by = "Grupo", alpha = 0.05) {
lvls <- levels(droplevels(data[[by]]))
x1 <- data %>% filter(.data[[by]] == lvls[1]) %>% pull(.data[[var]]) %>% na.omit()
x2 <- data %>% filter(.data[[by]] == lvls[2]) %>% pull(.data[[var]]) %>% na.omit()
if (length(x1) < 3 || length(x2) < 3) return("wilcox.test")
p1 <- tryCatch(shapiro.test(x1)$p.value, error = function(e) NA_real_)
p2 <- tryCatch(shapiro.test(x2)$p.value, error = function(e) NA_real_)
if (!is.na(p1) && !is.na(p2) && p1 > alpha && p2 > alpha) "t.test" else "wilcox.test"
}
tests_list <- setNames(
map(vNumericas, ~ elige_test(df, .x, by = "Grupo")),
vNumericas
)
tabla_test <- tibble(
variable = names(tests_list),
Test = case_when(
unlist(tests_list) == "t.test" ~ "t de Student",
unlist(tests_list) == "wilcox.test" ~ "Mann–Whitney",
TRUE ~ unlist(tests_list)
)
)
tab <- df %>%
select(all_of(c("Grupo", vNumericas))) %>%
tbl_summary(
by = Grupo,
type = list(all_continuous() ~ "continuous2", all_of(c("PAS","PAD")) ~ "continuous2"),
statistic = all_continuous() ~ c(
"{median} ({p25}, {p75})",
"{mean} ({sd})"
)
) %>%
add_p(test = tests_list) %>%
modify_table_body(
~ .x %>%
left_join(tabla_test, by = "variable")
) %>%
modify_header(Test ~ "**Prueba**") %>%
bold_labels()
tab| Characteristic | Tanger N = 30 |
Málaga N = 50 |
p-value1 | Prueba |
|---|---|---|---|---|
| Colesterol | <0.001 | t de Student | ||
| Median (Q1, Q3) | 165 (134, 199) | 203 (184, 238) | t de Student | |
| Mean (SD) | 163 (45) | 209 (42) | t de Student | |
| Trigliceridos | 0.018 | Mann–Whitney | ||
| Median (Q1, Q3) | 70 (57, 94) | 95 (66, 135) | Mann–Whitney | |
| Mean (SD) | 82 (45) | 113 (70) | Mann–Whitney | |
| Glucemia | <0.001 | Mann–Whitney | ||
| Median (Q1, Q3) | 75 (71, 82) | 84 (78, 90) | Mann–Whitney | |
| Mean (SD) | 78 (11) | 88 (19) | Mann–Whitney | |
| Pres. sistólica | 0.6 | Mann–Whitney | ||
| Median (Q1, Q3) | 120 (110, 125) | 120 (110, 130) | Mann–Whitney | |
| Mean (SD) | 120 (10) | 122 (13) | Mann–Whitney | |
| Pres. diastólica | 0.3 | Mann–Whitney | ||
| Median (Q1, Q3) | 70 (60, 80) | 70 (60, 80) | Mann–Whitney | |
| Mean (SD) | 73 (10) | 70 (10) | Mann–Whitney | |
| Peso | <0.001 | t de Student | ||
| Median (Q1, Q3) | 73 (65, 79) | 81 (75, 87) | t de Student | |
| Mean (SD) | 73 (8) | 81 (9) | t de Student | |
| Talla | 0.4 | t de Student | ||
| Median (Q1, Q3) | 170.0 (168.0, 174.0) | 170.0 (167.0, 172.0) | t de Student | |
| Mean (SD) | 170.3 (4.6) | 169.5 (4.7) | t de Student | |
| Consumo en Kcal | <0.001 | Mann–Whitney | ||
| Median (Q1, Q3) | 1,805 (1,580, 1,990) | 3,539 (3,176, 3,803) | Mann–Whitney | |
| Mean (SD) | 1,909 (470) | 3,528 (551) | Mann–Whitney | |
| Gasto en Kcal | 0.8 | t de Student | ||
| Median (Q1, Q3) | 1,865 (1,780, 2,030) | 1,895 (1,550, 2,179) | t de Student | |
| Mean (SD) | 1,894 (186) | 1,880 (438) | t de Student | |
| 1 Welch Two Sample t-test; Wilcoxon rank sum test | ||||